
| Author: Ashish Kumar | Published: 11-June-2026 |
What is Retrieval-Augmented Generation (RAG)?
Retrieval-augmented generation (RAG) is an AI architecture that connects a large language model to an external knowledge source before generating a response. Instead of relying solely on what the model learned during training, RAG retrieves relevant documents or data at the moment of the query and feeds that context to the LLM, producing answers that are grounded in verified, up-to-date information.
That single design choice solves the most persistent problem in enterprise AI: hallucination. Without RAG, a model can only guess at facts it may have learned, partially learned, or never encountered. With RAG, the model reads the source before it speaks. The result is traceable, auditable, and accurate.
RAG at Glance:
| Feature | RAG |
| Full Form | Retrieval-Augmented Generation |
| Purpose | Improve AI accuracy using external knowledge |
| Hallucination Reduction | 40-71% |
| Best For | Enterprise AI, Chatbots, Knowledge Management |
| Knowledge Updates | Real-time |
| Retraining Required | No |
| Source Attribution | Yes |
The global RAG market was valued at approximately USD $1.94 billion in 2025 and is projected to reach USD $9.86 billion by 2030, according to MarketsandMarkets. That growth is not speculative. It reflects how quickly enterprises are discovering that a well-designed retrieval layer is the difference between an AI tool people trust and one they quietly stop using. For organizations ready to act on that, purpose-built RAG Development Services are now the fastest path from pilot to production.
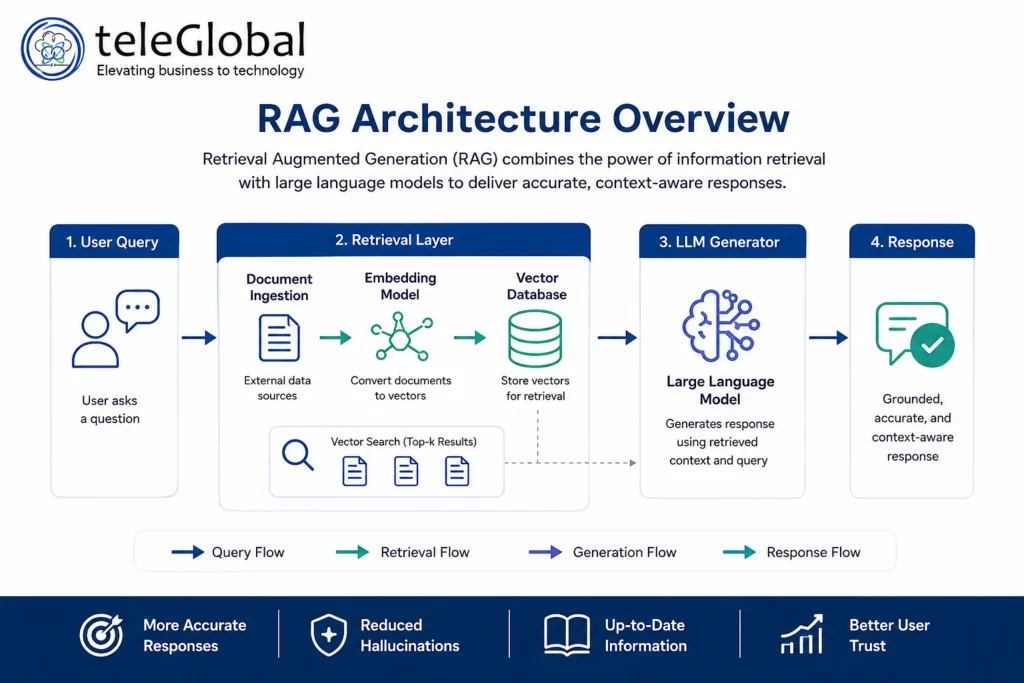
How RAG Architecture Works: A Step-by-Step Breakdown
RAG operates in a simple sequence. Each step is critical. Skipping or shortchanging any one of them degrades the output quality.
- User submits a query. A business user or application sends a natural-language question to the system.
- Query is converted into an embedding. The query is transformed into a numerical vector by an embedding model. This vector captures the semantic meaning of the question, not just its keywords.
- Vector database is searched. The system searches a pre-indexed vector database containing embeddings of the organization’s documents, policies, product data, or other knowledge. The most semantically similar chunks are retrieved.
- Retrieved context is ranked and filtered. A re-ranker evaluates the retrieved chunks and orders them by relevance. Only the highest-signal passages are passed forward.
- Context and query are combined into a prompt. The system assembles a prompt that includes the original question and the retrieved context. This combined prompt goes to the LLM.
- LLM generates a grounded response. The language model reads the retrieved context and generates an answer based on it, not from memory alone.
- Sources are cited and response is returned. The system returns the answer along with references to the specific documents retrieved, enabling users and auditors to verify every claim.
This architecture means that updating the AI’s knowledge is as simple as updating the document index. No retraining. No model downtime. No expensive GPU compute.
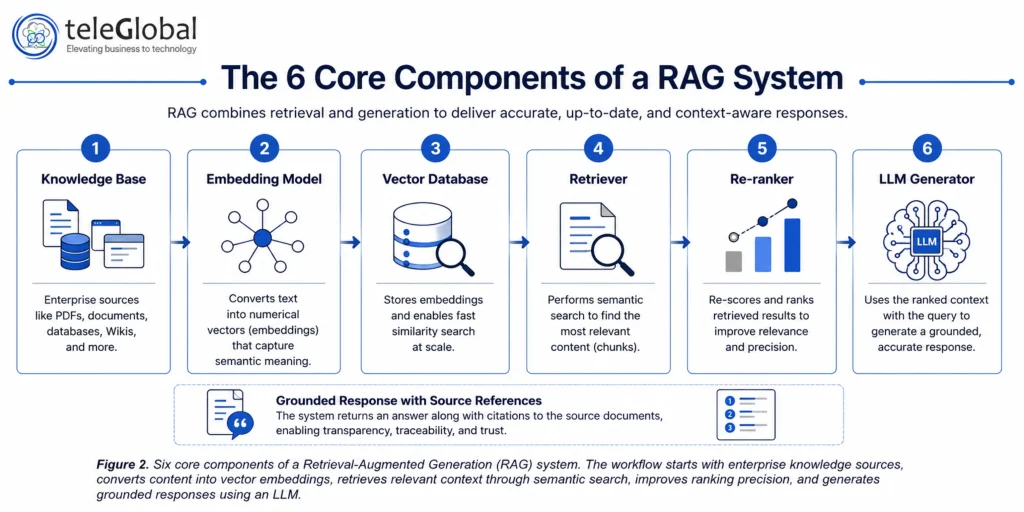
The Core Components of a RAG System
1. The Knowledge Base
This is the collection of documents, databases, PDFs, web pages, or structured records that the system retrieves from. Quality here determines everything downstream. A poorly curated knowledge base produces poor answers regardless of how sophisticated the retrieval and generation layers are.
2. The Embedding Model
This model converts text into numerical vectors. When documents are indexed, each chunk is embedded and stored. When a query arrives, it is embedded using the same model so that semantic similarity can be measured accurately. Popular choices include OpenAI Ada, Google Gecko, and open-source models like Sentence-BERT.
3. The Vector Database
A specialized database that stores embeddings and enables fast similarity search at scale. Enterprise deployments commonly use Pinecone, Weaviate, Chroma, Qdrant, or pgvector within PostgreSQL. These databases support millions of vectors with sub-second query times.
4. The Retriever
The retrieval layer executes the similarity search. Modern enterprise systems use hybrid retrieval, combining dense vector search with sparse keyword matching (BM25). Hybrid retrieval consistently outperforms single-method pipelines, particularly when document terminology varies from user query phrasing.
5. The Re-Ranker
After retrieval returns a set of candidate chunks, a cross-encoder re-ranker re-scores each result against the original query. This step significantly improves precision and reduces the noise that enters the LLM prompt.
6. The Generator (LLM)
The large language model receives the query and the retrieved context, then produces the final response. The LLM is not chosen for its memorized knowledge here; it is chosen for its ability to synthesize, summarize, and communicate the retrieved information clearly.
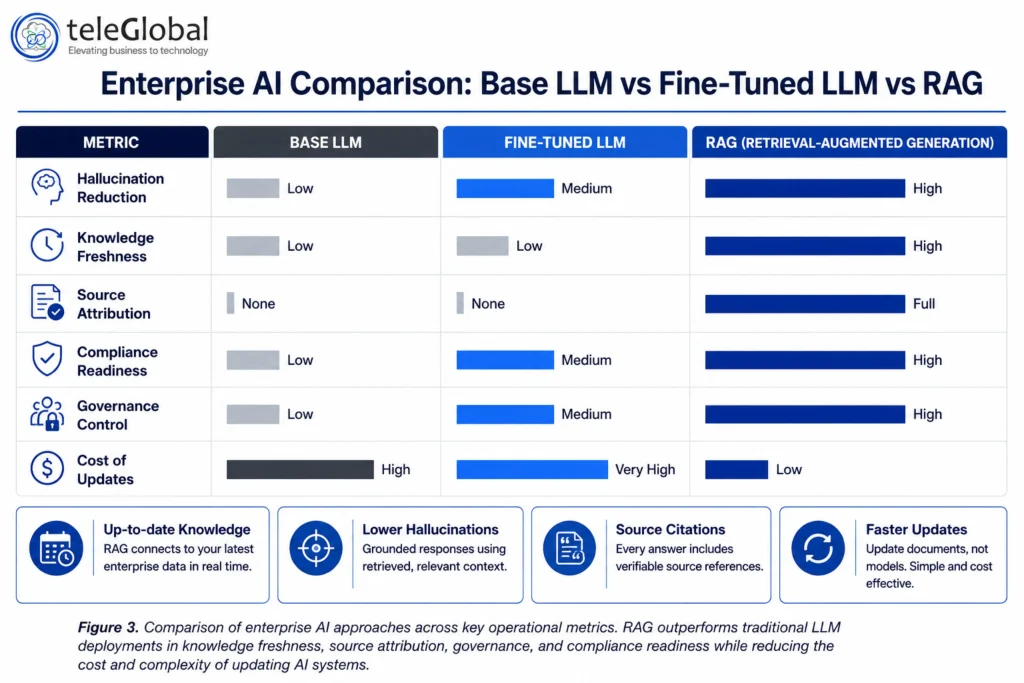
RAG vs. Fine-Tuning: Which Approach Is Right for Your Business?
Fine-tuning modifies a model’s weights by training it on additional data. It improves a model’s style, tone, or domain vocabulary but does not give it access to new facts after training ends. RAG, by contrast, does not change the model at all. It changes what the model can see at query time.
| Factor | RAG | Fine-Tuning |
| Knowledge updates | Real-time; update documents and re-index | Requires full model retraining |
| Cost to update | Low; only index changes | High; GPU compute for retraining |
| Hallucination risk | Significantly reduced (40-71% lower) | Higher; relies on memorized parameters |
| Source attribution | Yes; cites specific documents | No; outputs not traceable to source |
| Data governance | Strong; access controls enforced at query time | Weak; data baked into model weights |
| Best for | Frequently changing data, compliance-sensitive use cases | Specific tone, style, or task specialization |
| Deployment time | Days to weeks | Weeks to months |
For most enterprise use cases involving frequently updated knowledge, compliance requirements, or proprietary internal data, RAG is the more practical choice. Fine-tuning adds the most value when a specific response style or task specialization is required, and the two approaches can be combined for maximum effectiveness.
Why Enterprises Are Choosing RAG
Dramatically Fewer Hallucinations
RAG reduces AI hallucinations by 40 to 71 percent in document-intensive scenarios, according to multiple studies cited by AIMultiple and Blockchain Council. In a JMIR Cancer study, GPT-4 with RAG achieved a 0% hallucination rate on a specific task, compared to 6% without it. That difference has real consequences in healthcare, legal, and financial decisions.
Real-Time Knowledge Without Retraining
Enterprise data changes constantly. New products, revised policies, updated regulations, and fresh market data cannot wait for a model retrain cycle. A RAG system updates the moment the source document is indexed, which can happen in minutes.
Auditability and Compliance
Regulators in financial services, healthcare, and government increasingly require that AI-generated outputs be traceable to source documents. RAG provides exactly that: every response comes with a citation. Gartner projects that AI regulations will cover 50 percent of global economies by 2027, creating USD $5 billion in compliance investment. RAG is the architectural answer to that regulatory reality.
Cost Efficiency Compared to Retraining
Fine-tuning a large model to absorb new facts costs thousands to tens of thousands of dollars per run, requires data science expertise, and takes days. Updating a RAG knowledge base costs a fraction of that and can be automated. For organizations managing knowledge that changes weekly or monthly, this difference is significant.
Access Control and Data Governance
RAG retrieves documents based on the user’s permissions. A sales representative sees only the documents they are authorized to access. A finance analyst sees different content. This access-controlled retrieval is nearly impossible to replicate with a fine-tuned model, where proprietary information is baked into the weights and cannot be selectively hidden.
RAG Implementation Decision Framework
Before deploying RAG, business and technology leaders should match their specific requirements to the right architectural choices. Use this framework to assess readiness.
| Business Requirement | Condition | Recommended Approach |
| Data changes frequently | Yes | Use RAG with real-time indexing |
| Compliance/auditability required | Yes | RAG mandatory; enables source citation |
| Proprietary internal knowledge | Yes | RAG with access-controlled vector store |
| Specialized tone or domain style | Yes | Fine-tuning OR RAG + fine-tuning hybrid |
| Budget is limited | Yes | Start with cloud-based RAG (no GPU retraining) |
| Multimodal inputs (images, tables) | Yes | Multimodal RAG pipeline |
| On-premise data residency | Yes | On-premise RAG deployment |
RAG in Practice: Enterprise Use Cases
Financial Services
Banks and wealth management firms use RAG to give advisors instant access to research reports, regulatory updates, and client history. Instead of searching through siloed systems, a relationship manager can ask a single question and receive a synthesized answer with source citations.
Healthcare
Hospital systems deploy RAG to ground clinical decision support tools in current treatment guidelines, formulary data, and patient records. The JMIR Cancer study showing a 0% hallucination rate with RAG underscores why this matters in clinical contexts.
IT and Cloud Services
Technology companies and managed service providers use RAG to power intelligent support systems. At Teleglobal International, our RAG Development Services helps enterprises build RAG pipelines that draw on internal runbooks, incident logs, and knowledge bases to resolve support tickets faster and with verified information.
Legal and Compliance
Legal teams use RAG to interrogate contracts, policy libraries, and case archives. Rather than spending hours searching, counsel can query a RAG system and receive a precise, cited answer from the relevant clause or precedent.
Enterprise Knowledge Management
Organizations with large intranets, wikis, and document libraries deploy RAG to make institutional knowledge actually accessible. According to a McKinsey survey cited by Keerok, 71% of organizations now use generative AI Services in at least one business function. RAG is increasingly how that AI accesses the knowledge those organizations have spent years accumulating.
What to Get Right Before You Build
RAG architecture fails most often not because of the technology, but because of what feeds it. Three preparation steps make the difference between a working system and a costly disappointment.
- Clean the knowledge base first. Remove duplicates, outdated versions, and contradictory documents before indexing. Garbage in, garbage out applies with full force here.
- Choose chunking strategy deliberately. Documents should be split into semantically coherent sections, not arbitrary character counts. A paragraph about one topic should stay together. Breaking mid-sentence creates embedding noise that degrades retrieval accuracy.
- Implement hybrid retrieval from the start. Pure vector search misses exact-match terminology that users rely on. Combining dense embeddings with BM25 keyword search improves recall, particularly in technical and regulated domains.
- Add a re-ranker. The initial retrieval step returns candidates. A cross-encoder re-ranker improves the precision of what actually enters the prompt. This step is frequently omitted in proof-of-concept builds and frequently regretted.
- Monitor retrieval quality continuously. Track retrieval precision (are the right chunks being returned?), answer faithfulness (does the LLM stay grounded in what was retrieved?), and user feedback. These signals drive iterative improvement.
As an AWS Generative AI Competency partner, Teleglobal has deployed RAG pipelines on AWS Bedrock and Amazon Kendra for clients across India, the US, the UAE, and Europe. Our 10-plus years of cloud infrastructure experience means we understand not just the retrieval layer, but the data architecture, security controls, and cloud consulting practices that make enterprise RAG systems reliable at scale.
Frequently Asked Questions
1. What is retrieval-augmented generation in simple terms?
Retrieval-augmented generation (RAG) is an AI method that connects a language model to an external knowledge source. Before generating an answer, the system retrieves relevant documents from that source and provides them as context. This produces accurate, verifiable responses instead of answers based solely on the model’s training data.
2. What are the main components of a RAG architecture?
A RAG system has six core components: a knowledge base containing the source documents, an embedding model that converts text to vectors, a vector database that stores and searches those vectors, a retrieval layer that finds the most relevant chunks, a re-ranker that orders results by precision, and an LLM that generates the final response using the retrieved context.
3. How does RAG reduce AI hallucinations?
RAG grounds the LLM’s response in retrieved documents rather than model memory. Studies show RAG reduces hallucinations by 40 to 71 percent in document-based tasks. One JMIR Cancer study found that GPT-4 with RAG achieved a 0% hallucination rate on a specific task, compared to 6% without RAG. The model cannot fabricate what it has already been shown.
4. What is the difference between RAG and fine-tuning?
Fine-tuning retrains a model on new data, modifying its weights permanently. RAG leaves the model unchanged and instead gives it access to current documents at query time. Fine-tuning is better for style or task specialization. RAG is better for frequently updated knowledge, compliance requirements, and use cases that require source attribution.
5. When should a company use RAG?
Use RAG when your enterprise AI needs to answer questions using data that changes frequently, contains proprietary or confidential information, must be traceable for compliance purposes, or lives across multiple internal systems. RAG is the standard approach when accuracy and auditability are non-negotiable.
6. How much does it cost to implement RAG?
Cost varies by scale and approach. Cloud-based RAG can start at a few hundred dollars per month; organizations prioritizing speed often opt for RAG as a Service, where infrastructure is fully managed by a partner. Mid-scale enterprise systems typically cost USD $5,000 to USD $50,000 depending on data volume and customization. Ongoing costs include vector database hosting, embedding API calls, and LLM inference.
7. What are the best vector databases for enterprise RAG?
The most widely used options are Pinecone (managed cloud service, strong scalability), Weaviate (open-source with cloud option, strong filtering), Chroma (lightweight, good for prototyping), Qdrant (high-performance, self-hosted), and pgvector (PostgreSQL extension for teams already on Postgres). AWS offers Amazon OpenSearch and Kendra for Bedrock-integrated pipelines.
8. Can RAG work with structured data such as databases and spreadsheets?
Yes. Modern RAG systems can retrieve from structured databases using SQL-generation layers, spreadsheets via document parsing, and APIs via tool-calling architectures. Multimodal RAG extends this to images, tables, and audio. The key is building a preprocessing layer that converts structured records into retrievable chunks before indexing.
When Should You Invest in RAG Development Services?
Consider RAG if:
- Your employees spend hours searching documents.
- Customer support teams need instant answers.
- Compliance requires source-backed responses.
- Knowledge changes frequently.
- Internal information is spread across multiple systems.
Build Enterprise RAG With Teleglobal
Teleglobal International has designed and deployed AI systems for more than 900 clients across India, the US, the UAE, and Europe. As an AWS Generative AI Competency partner, we have hands-on experience building retrieval pipelines, vector databases, and LLM integrations that work reliably in production, not just in demos.
Whether you are exploring RAG for the first time or scaling a pilot to enterprise-wide deployment, our RAG Development Services cover architecture design, infrastructure selection, and end-to-end build – delivering systems your teams will actually use. We also bring data analytics and database management expertise to ensure your knowledge base is clean, current, and retrieval-ready.
Talk to a Teleglobal AI Architect
Contact Teleglobal International to discuss your RAG implementation